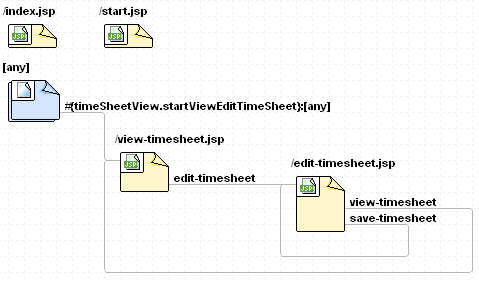
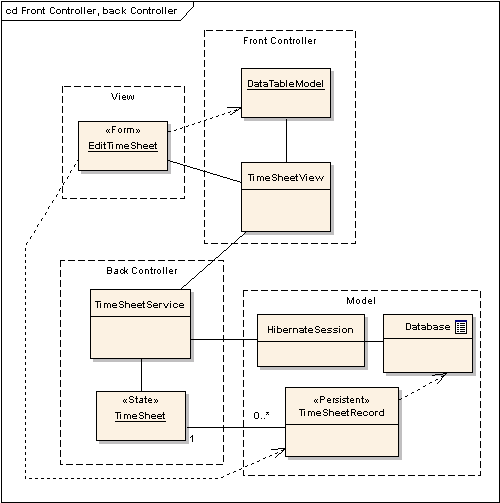
ORM 프래임워크의 대표격인 자바 기반의 하이버네이트 (Hibernate)의 레이지 로딩 (Lazy loading)에 대한 기사.
Lazy loading은 ORM의 성능에 있어서 아주 중요한 개념입니다.
————————————–
The Good, The Bad, and The Ugly
One of the potential problems with object/relational mapping is that a lot of work has to be done to convert relational results into object results. Because of the nature of an object-level querying and criteria system, the results returned by a query in an O/R mapping tool will potentially be much more coarse than what you might be able to achieve via standard JDBC calls. Tree structures are a great example of this. Say you had a class like this:
public class Node {
private List<Node> children;
private Node parent;
private String name;
public List<Node> getChildren() {
return children;
}
public Node getParent() {
return parent;
}
public void setChildren(List<Node> children) {
this.children = children;
}
public void setParent(Node parent) {
this.parent = parent;
}
// …
}
This Node class has a fairly complex set of associations; for a naive O/R mapper to provide an a fully populated Node object, it potentially would have to load the entire ‘Node’ table. For instance, given this tree:
-A
|
*—B
| |
| *—C
| |
| *—D
| |
| *—E
| |
| *—F
| |
| *—G
*—H
If you were to ask a naive O/R mapper to load C, it would have to load B (due to the parent reference). To load B, the O/R mapper then has to load D (due to the children reference). D then has to load E, F, and G. Then, to continue loading B, the O/R mapper has to load A, which then loads H. It’s possible that all we wanted was the name of C, however, and simply by loading C, we have loaded the entire tree. In the mean time, each association population would require a unique SQL select. By my count, that is around 8 gazillion SQL statements for just the example above, and the number of SQL statements grows *linearly* with the number of nodes in the data. The infamous n+1 problem; not a good performance statistic.
Let Sleeping O/R Mappers Lie (Get it? Hibernating? Nevermind…)
Hibernate is not a naive O/R mapper however. Instead, Hibernate does an excellent job of providing many APIs to minimize the impact of a query, and to make sure that you’re not doing too much work for the result you want. For one thing, Hibernate supports scalar queries, so you could simply get the name, and be done with it (that’s a discussion for another day however). In addition, if you really did need the whole tree, Hibernate supports join-style fetching so that the linear select situation can be minimized down to a couple (or even 1!) select statements (that is *also* a discussion for another day, however).
Hibernate is so Lazy!
Hibernate also supports the concept of ‘lazy’ fetching. Lazy interaction is discussed in more detail in Chapter 20 of the Hibernate 3.0 Reference Documentation. When working with Hibernate, it is *critical* to understand lazy associations, as they can be your best friend, but if you don’t treat them right, they can be your worst enemy. Besides, most lazy fetching strategies have been *enabled* by default in Hibernate 3.0!
Hibernate provides three forms of lazy fetching – lazy (single-point) associations, lazy collections, and lazy properties. Lazy collections have been around for a while in Hibernate, and they are the most commonly important form of lazy fetching. The children property of the Node class above is an example of a collection. Lazy (single-point) associations differ from collections by being single references to other objects persisted by Hibernate. So, the parent property of the Node class above is an example of an association. They are called single-point associations because if they were multi-point associations they would be a collection. From now on I’ll refer to single-point associations as just associations, because I’m lazy too. Finally, lazy properties could be values like name , that are typically mapped to a single column. This is rarely an important feature to enable (this, unlike other lazy fetching strategies in Hibernate 3, is disabled by default). It even says in the Hibernate documentation that ” Hibernate3 supports the lazy fetching of individual properties. This optimization technique is also known as fetch groups. Please note that this is mostly a marketing feature, as in practice, optimizing row reads is much more important than optimization of column reads. However, only loading some properties of a class might be useful in extreme cases, when legacy tables have hundreds of columns and the data model can not be improved.” . For that reason I intend to primarily discuss lazy associations and collections, as they are the more complicated to understand anyway. The same points I’ll make here apply for lazy properties as well as associations and collections.
Disclaimer on Lazy Associations
For lazy associations to work, the class containing the associations (in this case, the Node class) must either be a.) represented and retrieved via an interface or b.) not declared as final. This is because for the association relationships to be initialized after-the-fact, Hibernate has to instrument the class so that when ‘getParent()’ is actually called, it can go do the leg work at that time. It either has to do this through CGLIB, or through dynamic proxies. Dynamic proxies require an interface; CGLIB requires a non-final class. Note: at the time of this writing, CGLIB is *significantly* faster than dynamic proxies, but also requires more security access (doesn’t like sandboxes that restrict bytecode modification). So it is a tradeoff. For more information on these restrictions, see Section 5.1.4 .
Lazy collections don’t suffer from this problem, simply because Hibernate harbors custom implementations of the java.util.List , java.util.Map and java.util.Set interfaces (among others) that it sends to your class in place of default implementations (such as ArrayList ).
Atrophied Associations
In general practice, lazy collections and associations are managed by Hibernate transparently, to the point that you as a developer never have to worry about the fact that objects are only being loaded ‘as you need them’. Unfortunately, one of the most common patterns for Hibernate usage – inside an MVC web application – trips this transparent wire, setting off an anti-personnel mine of LazyInitializationException s. Too much ridiculous metaphor? Ok, let’s get into the real example.
In a general-case use, you might have code that looks like this:
Session s = getHibernateSession(); // get session from factory
try {
Query q = s.createQuery(“from Node n where n.name=:nodeName”).setString(“nodeName”, “C”);
Node cNode = (Node)q.uniqueResult(); // assuming Node with name C is unique…
Node cNodeParent = cNode.getParent();
System.out.println(“Node: “ + cNode.getName() + ” Parent: “ + cNodeParent.getName());
}
finally {
s.close();
}
This works perfectly, and you get a print-out of “Node: C Parent: B”, and Hibernate did it quite efficiently. Unfortunately, the modern pattern of a layered MVC web application causes a conflict with this. In an MVC web application you may have a servlet like this:
// Called via http://[server-name]/ListNodeAndParentServlet?nodeName=C
public class ListNodeAndParentServlet extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) {
String nodeName = request.getParameter(“nodeName”);
Node node = nodeDao.getNodeForName(nodeName);
request.setAttribute(“node”, node);
// forward to the JSP
request.getRequestDispatcher(“/nodeName.jsp”).forward(request, response);
}
}
Here is the DAO implementation:
public class NodeDao {
// …
public Node getNodeForName(String name) {
Session s = getHibernateSession();
try {
Query q = s.createQuery(“from Node n where n.name=:nodeName”).setString(“nodeName”, name);
Node node = (Node)q.uniqueResult(); // assuming Node with name ‘name’ is unique…
return node;
}
finally {
s.close();
}
}
}
… and here is a general sketch of the JSP:
<%
Node node = (Node)request.getAttribute(“node”);
%>
Name: <%=node.getName()%><br/>
Parent’s Name: <%=node.getParent().getName()%><br/> <!– This line would cause a LazyInitializationException! –>
As commented in the JSP, calling ‘getParent()’ on the node will attempt to load the parent node from the database, but because the NodeDao closed the session as soon as it was done with it, no further SQL statements can be executed, and Hibernate’s proxy around our Node throws a LazyInitializationException, complaining that we tried to get data that wasn’t loaded yet.
- Servlet asks DAO for object.
- DAO opens session, loads object, closes session. NO FURTHER SQL after this point
- Servlet puts node into request for view
- View requests necessary rendering information from node, such as parent. Exception is thrown due to 2.)
So, what is the solution?
Choose Your Poison
There are really two common answers to this problem as seen by the community right now. The first is to explicitly initialize all associations and collections required before returning it. The second is to keep the session open until the view is done rendering (commonly referred to as ‘Open Session In View’).
The latter solution (open session in view) typically requires that you have a robust ServletFilter that *always* closes the Session properly after that view has rendered. From the Hibernate documentation:
In a web-based application, a servlet filter can be used to close the Session only at the very end of a user request, once the rendering of the view is complete (the Open Session in View pattern). Of course, this places heavy demands on the correctness of the exception handling of your application infrastructure. It is vitally important that the Session is closed and the transaction ended before returning to the user, even when an exception occurs during rendering of the view. The servlet filter has to be able to access the Session for this approach. We recommend that a ThreadLocal variable be used to hold the current Session (see chapter 1, Section 1.4, ” Playing with cats “, for an example implementation).
The example described above is thorough enough that there is no reason to reproduce it here. Here is the general sketch of a servlet filter using the HibernateUtil class described in the previous link however:
public class SessionFilter implements Filter
{
private FilterConfig filterConfig;
public void doFilter (ServletRequest request,
ServletResponse response,
FilterChain chain)
{
try {
chain.doFilter (request, response);
}
catch(Exception e) {
// handle!
}
finally {
HibernateUtil.closeSession();
}
}
public FilterConfig getFilterConfig()
{
return this.filterConfig;
}
public void setFilterConfig (FilterConfig filterConfig)
{
this.filterConfig = filterConfig;
}
}
Then, you just need to modify the DAO to support this class:
public class NodeDao {
// implementation previously omitted.
public Session getHibernateSession() {
return HibernateUtil.currentSession();
}
public Node getNodeForName(String name) {
Session s = getHibernateSession();
Query q = s.createQuery(“from Node n where n.name=:nodeName”).setString(“nodeName”, name);
Node node = (Node)q.uniqueResult(); // assuming Node with name ‘name’ is unique…
return node;
}
}
Some developers consider this to be bad practice however (understandably so), because the transparent lazy fetching of the parent in the above example is not done until you are in your view rendering implementation. That means that if the SQL produced and executed by Hibernate throws any exceptions, or anything else goes wrong, your view is now responsible for handling it (e.g. your JSP); and as many of us have learned, one of the key benefits of this 2-step servlet-first approach is that any errors can be handled by the servlet, which a.) is more succeptible to pluggable error-handling approaches and b.) is prior to the response being committed, so error pages can still be loaded, etc.
Alternatively, the former solution (don’t remember the former solution anymore?) is to pre-load any resources you know you’re going to need in a view. This solution, while being more verbose, is perhaps more accurate, and provides more control if something were to go wrong. To do this, I typically still use the HibernateUtil solution. However, closing it as part of the servlet process itself (rather than through a filter) ensures that the session is out of the picture by the time the view is rendered. While this doesn’t allow the reusability of a filter, most developers now-a-days use an MVC framework such as Webwork (com.opensymphony.webwork.interceptor.*), Spring (org.springframework.web.servlet.HandlerInterceptor), or Struts (org.apache.struts.action.RequestProcessor), all of which support pluggable pre and post execution behaviors (similar to servlet filters, except only for the controller/action itself), and this behavior can certainly be done in those. For this simple example, however, I will simply put it in the code. Then, the trick is to simply initialize any associations required by the view. Simply accessing the association will initialize it:
node.getParent(); // this will cause the parent association to initialize.
// Called via http://[server-name]/ListNodeAndParentServlet?nodeName=C
public class ListNodeAndParentServlet extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) {
try {
String nodeName = request.getParameter(“nodeName”);
Node node = nodeDao.getNodeForName(nodeName);
// initialize associations
node.getParent();
request.setAttribute(“node”, node);
// forward to the JSP
request.getRequestDispatcher(“/nodeName.jsp”).forward(request, response);
}
catch(RuntimeException e) {
// handle runtime exception, forwarding to error page, or whatever
}
finally {
HibernateUtil.closeSession();
}
}
}
Note that if we had lazy property association on, we would need to call ‘getName()’ for the node and its parent node as well.
Collections require a little more work to initialize – you could of course, do it manually by traversing the entire collection, but it is perhaps better to call on the Hibernate utility class to do that for you. The Hibernate.initialize method takes an object as an argument, and initializes any lazy associations (this includes collections). So, if we wanted to fully initialize our node, and then fully initialize the collection of children:
Node n = // .. get the node
Hibernate.initialize(n); // initializes ‘parent’ similar to getParent.
Hibernate.initialize(n.getChildren()); // pass the lazy collection into the session to be initialized.
So, if our view was more like this:
<%
Node node = (Node)request.getAttribute(“node”);
%>
Name: <%=node.getName()%><br/>
Parent’s Name: <%=node.getParent().getName()%><br/> <!– This line would cause a LazyInitializationException! –>
Childrens’ Names: <br/>
<%
for(int i=0; i<node.getChildren().size(); i++) {
Node child = node.getChildren().get(i); // generics
if(i > 0) {
%>, <%
}
%><%=child.getName()%><%
}
%>
You would need the servlet (or wherever your object initialization code is) to do a little more legwork.
// Called via http://[server-name]/ListNodeAndParentServlet?nodeName=C
public class ListNodeAndParentServlet extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) {
try {
String nodeName = request.getParameter(“nodeName”);
Node node = nodeDao.getNodeForName(nodeName);
// initialize associations
Hibernate.initialize(node);
Hibernate.initialize(node.getChildren());
request.setAttribute(“node”, node);
// forward to the JSP
request.getRequestDispatcher(“/nodeName.jsp”).forward(request, response);
}
catch(RuntimeException e) {
// handle runtime exception, forwarding to error page, or whatever
}
finally {
HibernateUtil.closeSession();
}
}
}
I hope this gives you a starting point for understanding fitting lazy Hibernate collections and associations into a modern web application.